So, you’re interested in getting OnBase, but you’re currently using a legacy system. It’s time to bridge the gap between the two with a data migration.
The process of data migration transfers the data in your legacy system into your new OnBase system so it’s usable. If you’re like most organizations, however, you likely have high volumes of data to transfer, so the prospects of making this transfer can be nerve-wracking.
But that’s where we can help. At Naviant, we have extensive experience as a data migration partner helping clients successfully complete data migration projects of various scales and across industries, with recent projects including:
- Successful Migration of 180 Million Documents from SIRE (50+ Cabinets)
- 1.5 Billion Data and Document Migration from IBM FileNet Content Manager
- Migration from 1750 Lotus Notes Databases Contained Within a Single IBM Notes System
You can consider this 3-part blog your guide to data migration. It’s filled with best practices and tips we’ve learned from experience that’ll help you enter your own data migration project with added knowledge and confidence.
How to Convert Data with Integrity: Data Conversion Best Practices
Part 1: Data Complexity and Intermediate Validations
Is Data Certainty Possible?
Before anything else, how can there be certainty about data integrity during the conversion? To be frank, it is difficult, if not impossible, to begin assembling an accurate representation of data integrity when the conversion is already completed. As a result, we’ve found that the best approach is to think of the conversion as an exercise of maintaining data integrity.
With each step of data conversion services, think about how to validate. If there is an operation that produces a non-deterministic result or if the validation requirements are overly complex, then break up the operation into smaller, more manageable parts. The conversion should implement intermediate validations.
Know That Conversions are Complex
A typical conversion project involves more content than a group can inspect within a reasonable timeframe. Realistically, a person couldn’t even hope to review the content in a lifetime. Even more, data at volume is transient, which obstructs granular comparisons between systems. Additional factors make it difficult to start evaluating for data integrity at the end of conversion processing, like:
- Data transformations
- Business rules
- Heterogenous systems
- Data exclusions
- Complex data relationships
- Parent-child data
- Changing requirements
The Remedy: Intermediate Validations
Conversions are a form of pipeline processing where data flows through a series of interconnected steps. Each step receives the output from a previous step as input, executes a set of instructions, and passes the output to a subsequent step. Inline tests are used to verify the results of each instruction set; ensuring the data matches expectations before it is passed to a subsequent step. Data that fails a validation can be set aside, or the conversion pipeline can be configured to accommodate expected error conditions.
Tests in the pipeline can be applied to data either at the input or output of a pipeline step. Tests can also verify business logic.
Business logic tests validate assumptions about the data. For example:
- Isolate target data created in the last N years.
- Check that the item matches a defined mapping rule.
Input tests check data prior to each step in the conversion pipeline. For example:
- Verify the item meets threshold requirements for the step.
- Identify the data value is formatted appropriately before applying the transformation.
- Check for reprocess and handle subsequent processing correctly.
- Inspect date elements for unexpected values.
- All required elements contain a value and conform to formatting rules.
Output tests check the results of an operation. For example:
- The number of affected items match the expected amount based on input and reference data.
- The item references the correct number of children.
- Verify that default values exist only if necessary.
- Identify null or empty elements where values are expected.
Confidence with Conversion Pipeline
The conversion pipeline is a complex process with steps often too numerous to be monitored manually. Including intermediate validations helps to ensure data integrity by managing the data at each step. Used in conjunction with other methods, the conversion pipeline creates confidence in the conversion product.
Part 2: Situational Requirements and Error Isolation
Situational Requirements
If intermediate validations built into the conversion pipeline help to ensure the preservation of data integrity, then how does one put together a pipeline?
It is situational. The conversion pipeline is assembled based on requirements, which vary with every project. Though requirements are unique to each implementation, the approach to accommodate them is consistent. Moreover, many requirements are commonly encountered, thus standardizing whenever possible leads to a reduction of implementation time and likelihood of human error.
Consider the scenario wherein the database contains references to files on a network share. File paths are not explicitly stored, rather paths are calculated using specific column values. The requirement states that for each pointer calculated from the database, the actual file should be copied elsewhere in preparation of a subsequent pipeline flow.
The logical result might resemble:
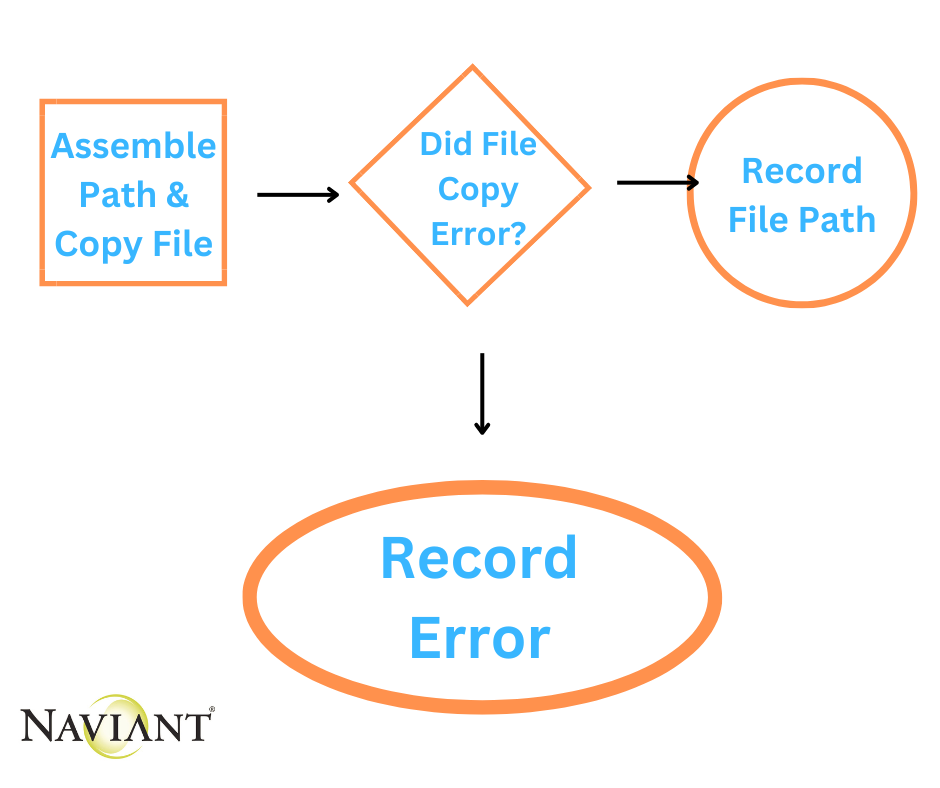
Error Isolation
An intermediate validation to check for an error is great. Would the file copy be the only point in the process that could generate an error? Is the failure to copy the file the only type of error that could occur? Could there be an error when calculating the file path? If so, does this flow allow easy distinction? Does a non-error necessarily mean that the file was deposited at the target location?
Looking at the pipeline flow does not communicate answers to questions like those, but such questions will occur. This pipeline does not adequately validate the processing step, nor does it appear to make the job of proving data integrity any easier.
Granular tracking of pipeline processes, especially at volume affords confident assurance of the job well done. Isolating data based on error condition promotes clarity about the status of conversion content and eliminates much of the effort during exception resolution. A more complete pipeline flow leveraging the concept error isolation could look like:
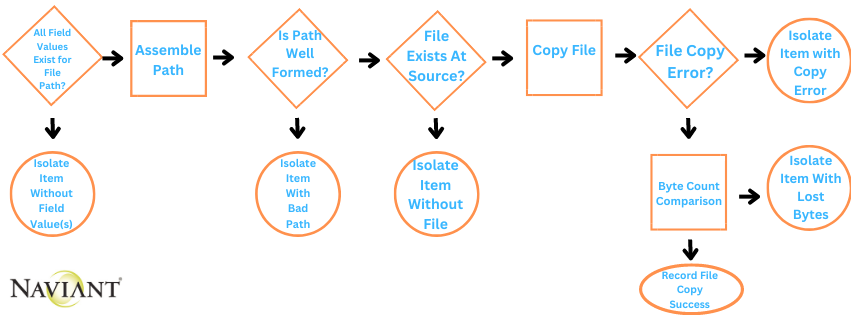
This pipeline flow breaks down the requirement into pieces. Each piece includes an intermediate validation that results in either the isolation of an error condition or the application of a subsequent operation. Deciphering an item with one type of problem from another is obvious. There can be confidence about items reaching the end for having passed the various validations along the way.
The form of each conversion pipeline is a response to business requirements and facts discovered among the data. Pipeline flows vary in number and complexity from one conversion to the next. Breaking down each requirement into a set of steps that can be easily tested and clearly interpreted is a key attribute of converting data with integrity.
Part 3: Minimizing Impact to Source System and Users
Conversion Impact
Responsibly implementing the conversion is more than moving content from the source to the target. Conversion processing has the potential to cause significant disruption to system resources. A negative impact to the availability of source data, end-user experience, and system load could be imposed during and because of the conversion. On the other hand, the conversion could be transparent to end-users without creating an unnecessary burden to the organization. That is not to say the conversion will never place added load on the source system, but the frequency, duration, and significance is largely determined by the conversion approach. It is entirely possible for a conversion to be low impact to the organization’s systems and users. The implementational choices can produce the outcome of a highly disruptive event or one that is not even noticed.
Establish a Point of Reference
How to implement a conversion that is transparent to end users? Avoid continuous interactions with the source system. Capture content from the source system on a regular interval. Use the conversion pipeline to establish point in time references. The conversion will operate without obstructing business operations and without competing for system resources.
Establishing a point of reference creates the following benefits:
Control
- Interact with the source systems under controlled and considered constraints
- Interactions with the source system are reduced to brief moments planned and scheduled to occur at specific times
- Selectively interact with only structures holding content relevant for conversion processing
- Complete or partial
- There are times when a complete snapshot is required, like at the start
- At later points, it is possible that only a subset of source system data needs to be obtained
- Completes rapidly with most often little to no perceptible impact by on the source system
Separation
- Maintain separation between compute resources dedicated to the conversion and those allocated to service the source system
- Creates a point-in-time reference required for effective validations
- Simplifies issue identification/resolution
- A dated reference facilitates setting expectations about what is contained among source data and identifying content that is not yet included
The primary goal of implementing a conversion is in maintaining data integrity, but as in life, be considerate of others. Even when a conversion project completes flawlessly, significant effort is required to ensure there is high confidence in its outcome. A conversion that causes a disturbance can make that job even more difficult.
Want More Content Like This?
Subscribe to the Naviant Blog. Each Thursday, we’ll send you a recap of our latest info-packed blog so you can be among the first to access the latest trends and expert tips on workflow, intelligent automation, the cloud, and more.





